Period: 2026-02-19. Substrate: + temporal difference value function (semi-gradient TD).
Hypothesis: Long-horizon prediction via value function V(s)=E[∑γtrt] integrates over all possible futures — inherently non-decomposable.
Metric
Seed 42
Seed 123
Seed 7
Mean
Mean robustness
1.034
0.998
1.003
1.012
Mean Φ
0.051
0.072
0.130
0.084
Final γ
0.748
0.746
0.741
0.745
Finding: Best robustness of any prediction experiment (1.012). Agents evolve moderate discount (γ≈0.75, horizon ~ 4 steps). But Φ is seed-dependent. The bottleneck is architectural: a single linear value readout doesn't force non-decomposable structure.
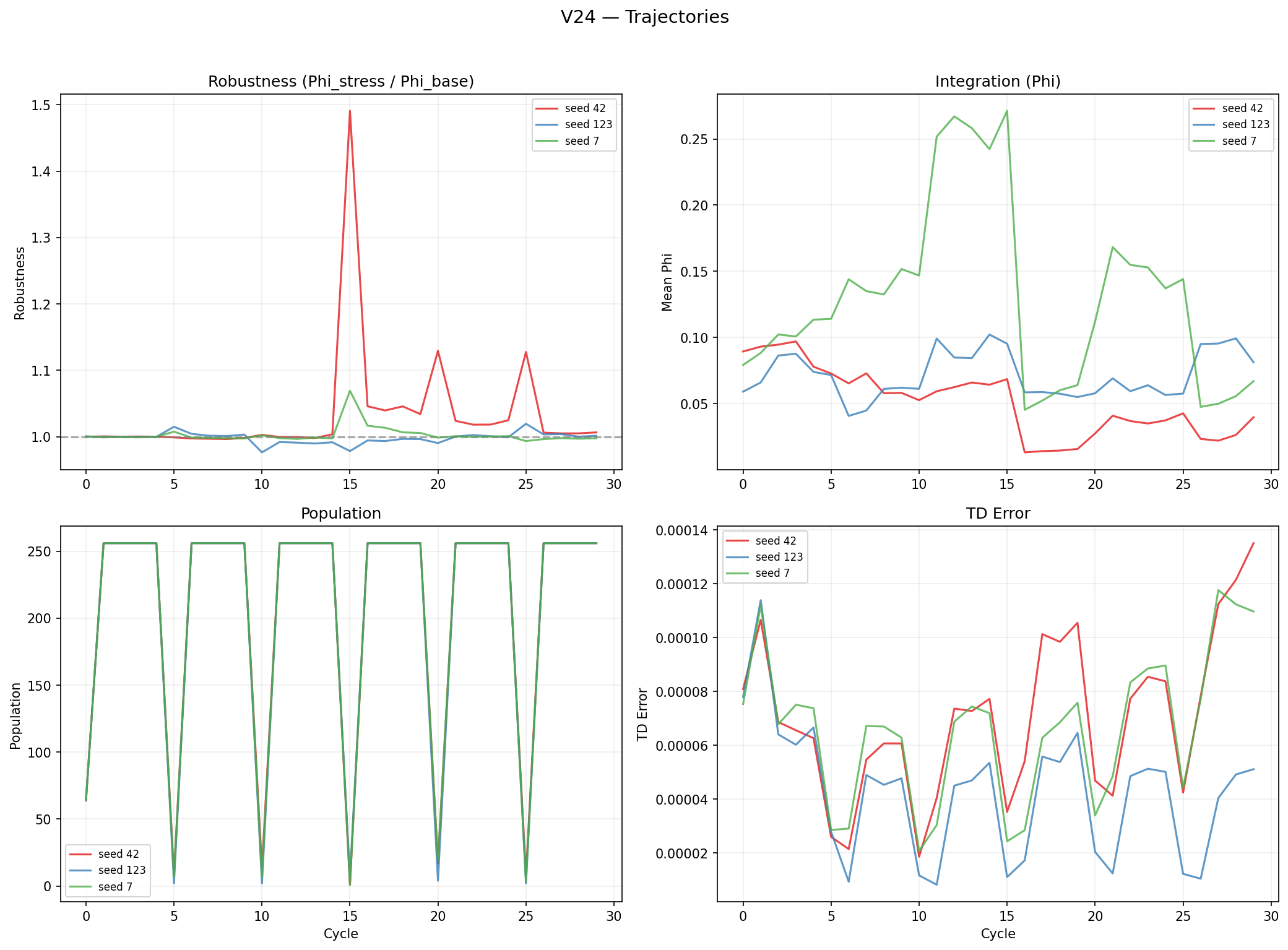
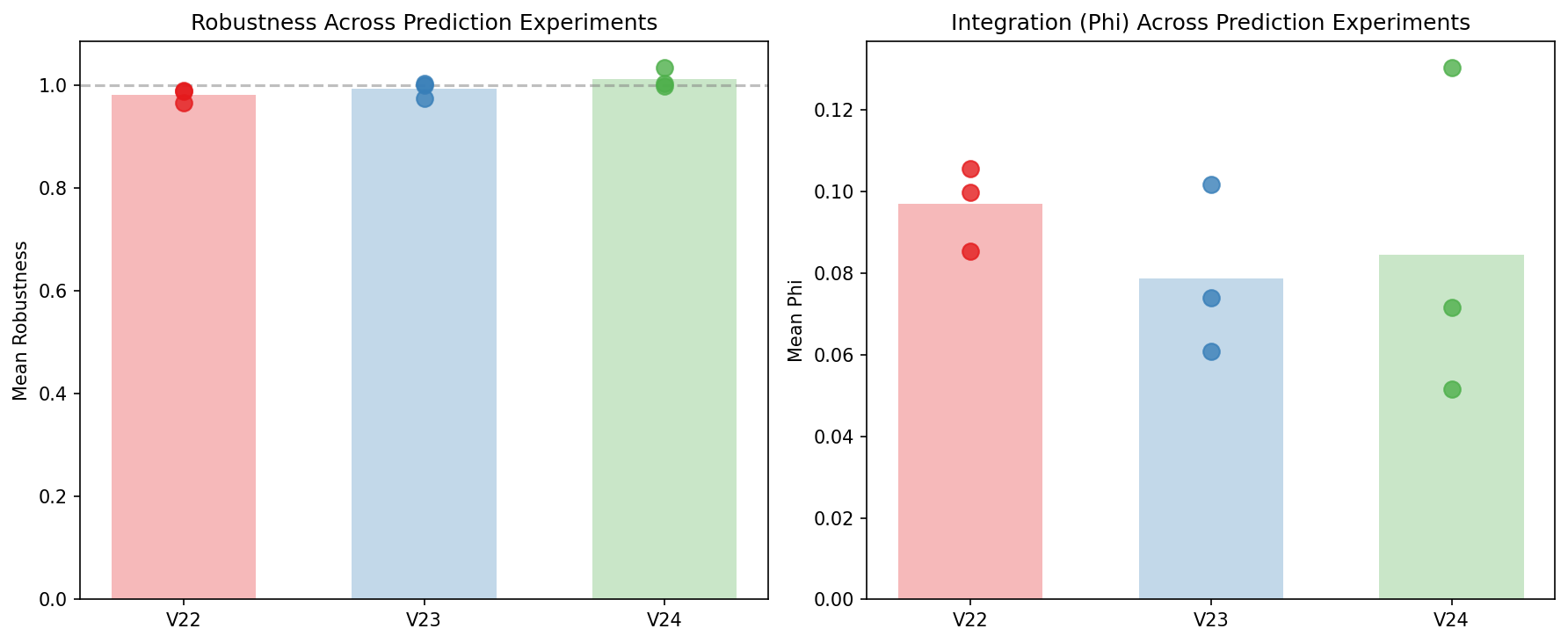
evolution trajectories. Top-left: robustness with dramatic spikes at drought boundaries (up to 1.5) — the highest transient robustness of any prediction experiment. Top-right: Φ shows the widest variance (0.02–0.25), with seed 7 reaching high values mid-evolution before declining. Bottom-left: population dynamics. Bottom-right: TD error decreases over evolution — value learning works, but doesn't force integration because the linear readout is decomposable. prediction experiment comparison. Left: mean robustness. (TD value) achieves the highest (~1.01), crossing the 1.0 threshold. and cluster below 1.0. Right: mean Φ. All three experiments overlap in the 0.06–0.10 range with high per-seed variance. Individual seed dots show no experiment consistently outperforms the others. The prediction target (scalar energy, multi-target, temporal value) does not reliably change integration — only architecture does (see V27).
Source code
Study record — canonical metadata, result path, status, seeds, and key finding.