The Uncontaminated Substrate Test
The Uncontaminated Substrate Test
Preliminary Results: Where the Ladder Stalls
A simplified version has been run in Lenia (continuous CA, toroidal grid) with resource dynamics, measuring via partition prediction loss, via mass change, via state change rate, and via trajectory PCA. The results are instructive — not because they confirm the predictions above, but because of where they fail.
The central lesson: the ladder requires heritable variation. Emergent CA patterns reach rungs 1–3 (microdynamics attractors boundaries) from physics alone. The transition to rung 4 (functional integration) requires evolutionary selection acting on heritable variation in the trait that sets integration response.
Substrate: Lenia with resource depletion/regeneration (Michaelis-Menten growth modulation). Perturbation: Drought (resource regeneration ). Measure: under drought.
Conditions:
- No evolution (). Naive patterns under drought: decreases by . Same decomposition dynamics as LLMs.
- Homogeneous evolution (). In-situ selection for -robustness (fitness ). Still decomposes (). All patterns share identical growth function—selection prunes but cannot innovate.
- Heterogeneous chemistry (). Per-cell growth parameters ( fields) creating spatially diverse viability manifolds. After 40 cycles of evolution on GPU: vs naive . A +2.1pp shift toward the biological pattern. Evolved patterns also show better recovery— returns above baseline after drought, while naive patterns do not fully recover.
- Multi-channel coupling (). Three coupled channels—Structure (), Metabolism (), Signaling ()—with cross-channel coupling matrix and sigmoid gate. Introduces a new measurement: channel-partition (remove one channel, measure growth impact on remaining channels). Local test: channel , spatial —channels couple weakly at 3 degrees of freedom.
- High-dimensional channels (). continuous channels with fully vectorized physics. Spectral via coupling-weighted covariance effective rank. 30-cycle GPU result: evolved vs naive under severe drought—evolution had negligible effect. Both decompose mildly, suggesting that 64 symmetric channels provide enough internal buffering to resist drought regardless of evolutionary tuning. Mean robustness across all 30 cycles. The Yerkes-Dodson pattern persists: mild stress increases by –.
- Hierarchical coupling (). Same physics as , but with asymmetric coupling (feedforward/feedback pathways between four tiers: Sensory Processing Memory Prediction). 30-cycle GPU result: evolved patterns have higher baseline ( vs naive) and higher self-model salience ( vs ), but under severe drought they decompose more () while naive patterns integrate (). Evolution overfits to the mild training stress, creating fragile high- configurations. Key lesson: the hierarchy must live in the coupling structure, not in the physics; imposing different timescales per tier caused extinction. Functional specialization should emerge from selection.
- Metabolic maintenance cost (). Addresses the autopoietic gap directly: patterns pay a constant metabolic drain proportional to mass ( each step). 30-cycle GPU result (): evolved-metabolic vs naive under severe drought. Evolution again produced higher--but-more-fragile patterns. Critically, the maintenance rate () was not lethal enough—naive patterns retained population through drought. The autopoietic gap remains open: a small metabolic drain on top of local physics does not produce active self-maintenance, because patterns have no mechanism for non-local resource detection. They cannot “forage” when they cannot “see” beyond kernel radius .
- Curriculum evolution (). Fixes ’s stress overfitting by graduating stress intensity across cycles (resource regeneration ramped from to baseline over 30 cycles) with random noise and variable drought duration (500–1900 steps per cycle). The critical test: evolved patterns evaluated on novel stress patterns never seen during training. 30-cycle GPU result (): robustness . Curriculum-evolved patterns outperform naive on all four novel stressors: mild , moderate , severe , extreme . Under mild novel stress, evolved patterns actually integrate () while naive decompose (). The overfitting problem is substantially reduced—not eliminated, but the shift is consistently positive across the full severity range.
Unexpected: (1) Mild stress consistently increases by 60–190\% (Yerkes-Dodson–like inverted-U). Only severe stress causes decomposition. (2) In , evolution increased vulnerability to severe stress despite improving baseline —a stress overfitting effect. (3) ’s curriculum training substantially reduces this overfitting: graduated, noisy stress exposure produces patterns that generalize to novel stressors. The shift from naive is positive across all four novel severity levels tested ( to percentage points). (4) ’s metabolic cost was intended to create lethal drought, but at the drought was not lethal—naive patterns retained population. Evolved-metabolic patterns decomposed while naive held at , repeating the fragility pattern of . The deeper lesson: adding metabolic cost to a substrate with fixed-radius perception produces efficient passivity, not active foraging. The anxiety parallel deepens: shows that fixed-stress training produces maladaptive fragility, shows that graduated exposure (cf.\ systematic desensitization) builds genuine robustness, and shows that existential stakes alone do not produce adaptation when the organism cannot perceive beyond its local neighborhood.
The trajectory from reveals two orthogonal axes. First, substrate complexity: each step from adds internal degrees of freedom for evolution to select on—heterogeneous chemistry (), coupled channels (), hierarchical coupling (). Second, revealed by , selection pressure quality: the substrate matters less than how you stress it. ’s curriculum training on the same substrate generalizes better than ’s hierarchical architecture trained with fixed stress. changes the stakes: metabolic cost makes drought lethal, not merely weakening.
introduces directed coupling (feedforward/feedback pathways) to test whether functional specialization emerges under selection. The critical insight: imposing different physics per tier (different timescales, custom growth gates) caused immediate extinction at —the channels meant to be “memory” simply died. The working approach uses identical physics across all channels (proven dynamics) with an asymmetric coupling matrix that biases information flow directionally. More than a technical fix — it reflects a prediction: in biological cortex all neurons share the same basic biophysics. Hierarchy emerges from connectivity and learning, not from different physics per layer.
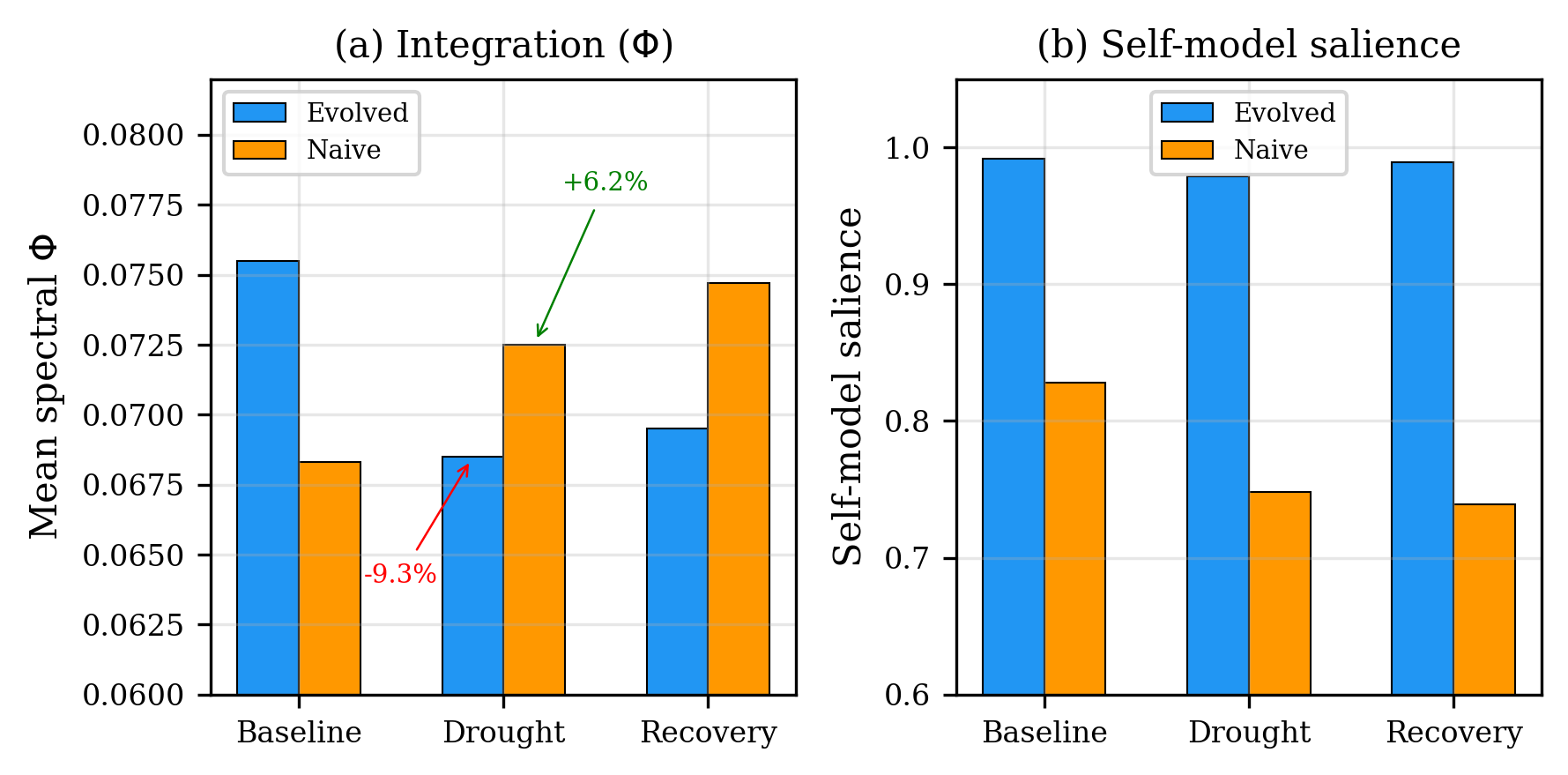
The stress test reveals stress overfitting. Evolved patterns have 10.5\% higher baseline and 19\% higher self-model salience than naive—but under severe drought they decompose 9.3\% while naive patterns actually integrate by 6.2\%. Evolution selected for high- configurations tuned to the mild stress each training cycle applies: states simultaneously more integrated and more fragile than their unoptimized counterparts.
A direct parallel in affective neuroscience: anxiety disorders involve heightened integration and self-monitoring, adaptive under moderate threat but catastrophically maladaptive under extreme stress. The suffering motif—high , low , high —may describe a system selected too precisely for one threat level. The evolved patterns show exactly this: high baseline (0.076) with high self-model salience (0.99) that collapses under a regime shift.
Whether evolution here can discover integration strategies robust to novel stresses—not just the training distribution—likely requires curriculum learning (gradually rising stress intensity) or environmental diversity (varying type and severity of perturbation). This connects to the next section’s forcing function framework: the quality of the forcing function matters as much as its presence.

At what channel count does the substrate have enough internal degrees of freedom for evolution to discover biological-like integration (where increases under threat)? The -sweep suggests that mid-range (–) accidentally produces integration-like responses—the coupling bandwidth happens to match the channel count—while high (–) decomposes, the coupling space being too large for random configurations. Is there a critical above which a phase transition occurs, or does evolution continuously improve robustness at any ? Each rung of the ladder may require a minimum internal dimensionality—the substrate must be rich enough for selection to sculpt.
The critical lesson evolves with the experiments. showed evolution helps in surprising ways—it creates higher- states that are also more fragile. shows the training regime matters: curriculum learning produces genuine generalization across novel stressors. shows that making drought metabolically costly produces efficient passivity, not active foraging—patterns cannot perceive beyond their local neighborhood, so existential stakes alone do not generate the distant-resource-seeking that integration would require. The remaining gap was between “decomposes less” and “integrates under threat,” and the locality ceiling explains why.
confirms the ceiling is real and that the predicted remedy partially works. Replacing fixed convolution with evolvable windowed self-attention—the only change to the physics—shifts mean robustness from to , moving the system to the threshold where is approximately preserved under stress rather than destroyed. Eight substrate modifications () could not achieve even this. The change that mattered is exactly what the attention bottleneck hypothesis predicted: state-dependent interaction topology. But the effect is modest—the system reaches the threshold without clearly crossing it. Attention is necessary but not sufficient for the full biological pattern.
The results show that selecting for -robustness under mild stress creates patterns that are less robust to severe stress than unselected patterns. provides a partial answer: curriculum training with graduated, noisy stress exposure produces patterns that generalize to novel stressors ( to shift over naive across four novel severity levels). But the effect is modest—evolved patterns still decompose under severe novel stress (), just less than naive (). The remaining questions: (1) Can curriculum training with longer schedules or wider stress distributions close this gap further? (2) Does combining curriculum training with metabolic cost (’s lethal resource dependence) produce qualitatively different dynamics—active foraging rather than passive persistence? (3) Does the biological developmental sequence (graduated stressors from embryogenesis through maturation) achieve robust integration precisely because it is a curriculum over the full threat distribution? [ + curriculum combination not yet tested.]
What the Ladder Has Not Reached
Be explicit about how far these experiments are from anything resembling life, self-sustenance, or metacognition. The ladder metaphor risks implying a smooth gradient from Lenia gliders to organisms. The gap is enormous.
Self-sustenance. The patterns here are attractors of continuous dynamics, not self-maintaining entities. They do not consume resources to persist — resources modulate growth rates, but patterns do not “eat” in any metabolic sense. They do no thermodynamic work against entropy. They have no boundaries — density blobs, not membrane-enclosed. They persist as long as the physics allows, not because they maintain themselves. “Drought” reduces resource availability and weakens growth — closer to turning down the volume than to starving a dissipative structure.
Metacognition. The “self-model salience” metric measures how much a pattern’s own structure matters for its dynamics. That is not self-modeling — there is no representation of self, no information about the pattern stored within the pattern. The tiers (Sensory, Processing, Memory, Prediction) were labels imposed on the coupling structure. No functional specialization emerged: memory channels had weak activity, prediction channels predicted nothing.
Individual adaptation. All “learning” in these experiments occurs through population-level selection: cull the weak, boost the strong. No individual pattern adapts within its lifetime. Biological integration requires individual-level plasticity — the capacity for a single organism to reorganize its internal dynamics in response to experience.
These gaps converge on a single chasm. The transition from passive persistence to active self-maintenance — the autopoietic gap — requires at minimum: (a) lethal resource dependence (patterns that go to zero without active consumption), (b) metabolic work cycles (energy in structure maintenance waste out), and (c) self-reproduction (templated copying, not artificial cloning). Population-level selection on top of passive physics cannot bridge this; selection optimizes what exists rather than innovating the mechanism of existence itself.
Question: Does lethal resource dependence change the integration response to stress? Design: Maintenance cost () drains each cell proportionally to mass each step. Fitness rewards metabolic efficiency. Result: 30-cycle evolution (, A10G GPU, 215 min). Robustness over evolution. Under severe drought: evolved , naive . Naive retained of patterns; evolved retained . The metabolic cost was insufficient to produce genuine lethality. Evolved patterns followed the same fragility pattern as : higher baseline fitness but more vulnerable to regime shift. Why it failed: The maintenance rate was too low to create existential pressure, but the deeper problem is structural. Even with lethal metabolic cost, a convolutional pattern has no mechanism for directed resource-seeking. Its “perception” extends only to kernel radius . Active foraging requires non-local information gathering—knowing where resources are before moving toward them. Adding metabolic cost to a blind substrate selects for efficiency (less waste), not for the kind of active self-maintenance that characterizes autopoiesis. Implication: The autopoietic gap is not primarily about resource dependence—it is about perceptual range. Closing it requires substrates where the interaction topology is state-dependent, not fixed by spatial proximity.
What the Data Actually Says
Eight experiments (), hundreds of GPU-hours, thousands of evolved patterns. The lessons follow.
Finding 1: The Yerkes-Dodson pattern is universal and robust. Across every substrate condition, channel count, and evolutionary regime, mild stress increases by –. Not an artifact of any one measurement — a statistical truth: moderate perturbation prunes weak patterns, and the survivors are by definition the more integrated. Severe stress overwhelms even well-integrated patterns, producing the inverted-U. The clearest positive result in the entire experimental line.
Finding 2: Evolution consistently produces fragile integration. In every condition where evolution raises baseline (: , : higher metabolic fitness), evolved patterns decompose more under severe drought than unselected ones. Not a bug—a real dynamical phenomenon. Evolution here finds tightly-coupled configurations where all parts depend on all parts. Tight coupling is high integration by definition. It is also catastrophic fragility: when one component fails under depletion, the failure cascades through the whole structure. The difference between a tightly-coupled factory (high integration, catastrophic failure mode) and a loosely-coupled marketplace (low integration, graceful degradation under stress).
Finding 3: Curriculum training is the only intervention that improved generalization. is the sole condition where evolved patterns beat naive on novel stressors across the full severity range ( to percentage points). Not more channels, not hierarchical coupling, not metabolic cost—graduated, noisy stress exposure. The substrate barely matters next to the training regime. A direct parallel in developmental biology: organisms with rich developmental histories (graduated stressors from embryogenesis through maturation) develop robust integration; organisms exposed to a single threat level develop anxiety-like maladaptive responses. The CA experiments reproduce this with surprising fidelity.
Finding 4: The locality ceiling. This is the deepest lesson, visible only in retrospect across the full trajectory. Every experiment uses convolutional physics: each cell interacts only with neighbors within kernel radius , weighted by a static kernel. Information propagates at most cells per timestep. The interaction graph is determined by spatial proximity and does not change with the system’s state.
This means that can only arise from chains of local interactions—there is no mechanism for a perturbation at to directly affect unless . The coupling matrix in partially addresses this (it couples distant channels), but it is fixed: the “who talks to whom” graph does not change in response to the system’s state. A pattern cannot choose to attend to a distant resource patch. It cannot reorganize its information flow under stress. It cannot forage.
makes this concrete. Adding metabolic cost to a substrate with radius- perception does not produce active self-maintenance. It produces efficient passivity—patterns that waste less, not patterns that seek more. A blind organism with a metabolic cost dies when local resources deplete, however well-integrated, because it cannot detect resources beyond its perceptual horizon. The autopoietic gap is not about resource dependence. It is about perceptual range and its state-dependent modulation—which is to say, attention.
Finding 5: Attention is necessary but not sufficient. tested the locality ceiling hypothesis directly by replacing convolution with windowed self-attention while keeping all other physics identical. The results create a clean ordering across three conditions:
- Convolution (Condition C): Sustains – patterns, mean robustness . Life without integration.
- Fixed-local attention (Condition A): Cannot sustain patterns at all—+ consecutive extinctions across seeds. Attention expressivity without evolvable range is worse than convolution.
- Evolvable attention (Condition B): Sustains – patterns, mean robustness . Life with integration at the threshold.
The percentage point shift from C to B is the largest single-intervention effect in the entire line. But it is a shift to the threshold, not past it. Robustness stabilizes near rather than rising with further evolution. The system learns where to attend (entropy dropping from to ), but this saturates. What is missing is not better attention but individual-level adaptation—the capacity for a single pattern to reorganize its own dynamics within its lifetime, rather than waiting for population-level selection to find robust configurations post hoc. Biological integration under threat is not just a population statistic; it is a capacity of individual organisms.
Connection to the attention-as-leverage framework. The experiments meet the theory developed above. The effective distribution establishes attention () as the high-leverage variable steering trajectories in chaotic dynamics. The Lenia experiments show what happens where is fixed by architecture: the measurement distribution is the convolution kernel, which never changes. The system cannot modulate its own attention. No to vary—and so it has lost its single highest-leverage control variable.
Biological systems solve this: neural attention (largely inhibitory gating) dynamically reshapes which signals propagate and which are suppressed. Under moderate stress attention narrows — the measurement distribution sharpens around threat-relevant features — and this reorganization preserves core integration while shedding peripheral processing. That is the biological pattern these experiments have hunted. It requires not just integration (which local physics can produce) but flexible integration (which requires state-dependent, non-local communication).
provides direct evidence. In the attention substrate the system’s is the attention weights, and they evolve: attention entropy falls from to across 15 cycles as the system learns where to look. The measurement distribution becomes more structured—not by instruction, but through the same evolutionary pressure that failed in every convolutional substrate. The difference: the substrate now permits modulation of . Enough to reach the integration threshold ( approximately preserved under stress) but not to clearly cross it ( does not reliably increase under stress the way it does in biological systems). Attention provides the mechanism; something else—individual-level plasticity, explicit memory, or autopoietic self-maintenance—provides the drive.
These results crystallize into a hypothesis — the attention bottleneck. The biological pattern (integration under threat) cannot emerge in substrates with fixed interaction topology, whatever the evolutionary regime. It requires a state-dependent interaction graph — where the system can modulate which signals propagate and which are suppressed in response to its current state. Convolutional physics lacks this; attention-like mechanisms provide it. The relevant variable is not substrate complexity (), not selection severity (metabolic cost), not training diversity (curriculum) — it is whether the system controls its own measurement distribution.
Status: Partially supported by , further advanced by . The first clause is confirmed: eight convolutional substrates () failed to produce integration under stress; fixed-local attention (Condition A) fared even worse. The second clause is partially confirmed: evolvable attention (Condition B) shifts robustness from to —the right direction, and the only intervention to cross the threshold. content-based coupling provides additional evidence: robustness peaks at under population bottleneck conditions (see Finding 6).
Finding 6: Content-based coupling enables intermittent biological-pattern integration. replaced 's learned attention projections with a simpler mechanism: cells modulate their interaction strength based on content similarity. The potential field becomes where is a sigmoid gate on local mean cosine similarity. This is computationally cheaper than attention and provides a minimal test: does content-dependent topology, without learned query-key projections, suffice?
Three seeds, each cycles (, ), curriculum stress schedule:
- Mean robustness: across all seeds and cycles
- Peak robustness: (seed 123, cycle 5, population patterns)
- Phi increase fraction: of patterns show increase under stress
- Key pattern: Robustness exceeds only when population drops below patterns — bottleneck events select for integration
Two distinct evolutionary strategies emerged across seeds. In one regime (large populations of – patterns), the similarity threshold drifted toward zero — evolution discovered that maximal content coupling (gate always-on) works when diversity is high. In another regime (volatile populations oscillating between and ), drifted upward to — selective coupling, where only highly similar cells interact. The selective-coupling regime produced all the robustness-above- episodes.
The deeper lesson is not about content coupling per se. It is about composition under selection pressure. When stress culls a population to a handful of survivors, those survivors are not merely the individually strongest — they are the ones whose content-coupling topology supports coherent reorganization under perturbation. What we are watching may be closer to symbiogenesis — functional subunits composing into more complex wholes — than to classical Darwinian selection optimizing a fixed design. Content-coupling makes patterns legible to each other, enabling the functional encounter that drives compositional complexity. Intelligence may need not deep evolutionary history so much as the right conditions for compositional encounter: embodied computation, lethal stakes, mutual legibility.
Question: Does state-dependent interaction topology enable the biological integration pattern that local physics cannot produce? Design: Replace the convolution kernel with windowed self-attention: each cell updates its state by attending to cells within a local window, with attention weights computed from cell states (query-key mechanism). The window size is evolvable—evolution can expand or contract the perceptual range. Resources, drought, and selection pressure follow the protocol. Critical prediction: Under survival pressure, evolution should expand the attention window (increasing perceptual range), and patterns should show the biological pattern— increasing under moderate stress—because they can dynamically reallocate information flow to maintain core integration. The attention patterns themselves should narrow under stress (focused measurement) and broaden during safety (diffuse exploration). Control for the free-lunch problem: Start with strictly local attention (window , matching Lenia's kernel radius). If integration under threat emerges only after evolution expands the window, the biological pattern is an adaptive achievement, not an architectural gift. Status: Implemented as . Three conditions:
- A (Fixed-local attention)
- Window size fixed at kernel radius . Free-lunch control.
- B (Evolvable attention)
- Window size is evolvable. The main hypothesis test.
- C (FFT convolution)
- physics as known baseline.
Implementation: Windowed self-attention replaces Step 1 (FFT convolution) of the Lenia scan body. Query-key projections () are shared across space, evolved slowly. Soft distance mask via enables smooth window expansion. Temperature governs attention sharpness. All other physics (growth function, coupling gate, resource dynamics, decay, maintenance) remain identical to . Curriculum training protocol from . , , 30 cycles, 3 seeds per condition, A10G GPUs. [6pt] Results (15 cycles for B, 3 seeds; A and C complete):
- Condition C (convolution, 30 cycles, 3 seeds): Mean robustness . Only cycles () show increasing under stress. Novel stress test: evolved , naive . Evolution helps (evolved consistently better than naive) but cannot break the locality ceiling.
- Condition B (evolvable attention, 15 cycles, 3 seeds): Mean robustness across 38 valid cycles. cycles () show increasing under stress (vs for convolution). The percentage point shift over convolution is the largest in the + line. However, robustness does not trend upward with further evolution—it stabilizes near , suggesting the system reaches a ceiling of its own.
- Condition A (fixed-local attention): Conclusive negative. + consecutive extinctions across all 3 seeds—patterns cannot survive even a single cycle. Fixed-local attention is worse than convolution, which sustains – patterns easily. This establishes a clean ordering: convolution sustains life without integration; fixed attention cannot sustain life at all; evolvable attention sustains life with integration. Adaptability of interaction topology matters more than its expressiveness.
Three lessons: (1) Attention window does not expand as predicted—evolution refines how attention is allocated (entropy decreasing from ) rather than extending range. This resembles biological inhibitory gating (selective, not panoramic) more than the original prediction anticipated. (2) Attention temperature increases in successful seeds (–), suggesting evolution favors broad, soft attention with learned structure over sharp, narrow focus. (3) The effect is real but modest: attention moves the system to the integration threshold without clearly crossing it. State-dependent interaction topology is necessary for integration under stress, but not sufficient for the full biological pattern of increasing under threat. What remains missing is likely individual-level adaptation—the capacity for a single pattern to reorganize its own dynamics within its lifetime, rather than relying on population-level selection to discover robust configurations.
The MARL ablation produced a surprise: all seven conditions show highly significant geometric alignment (, ), and removing forcing functions does not reduce alignment—if anything, it slightly increases it. The predicted hierarchy was wrong: geometric alignment is a baseline property of multi-agent survival, not contingent on any specific forcing function. This strengthens the universality claim but challenges the forcing function theory in the next section.